AUTEUR: NIELS MEIJER CORE DEVELOPER FRANK!FRAMEWORK
In our previous blog, we talked about our streaming capabilities in the Frank!Framework (blog.wearefrank.nl/en/streaming), but how does such a thing work technically?
Streaming basically means that you don't have to load large objects, for example files, entirely into memory before you can start processing them. The building blocks from the Frank!Framework are given a "handle" to an input and/or output stream on the basis of which they can already start their processing on a part of the data.
Let's divide it into two parts initially, process an incoming stream inputStream and process an outbound stream outputStream.
USING AN INPUT STREAM:
Example: Process file from a streaming directory.
We have one file on the FileSystem that contains a collection of records to process.
The Frank Adapter starts and makes an input stream available to each of the (iterator) building blocks in the adapter. This building block reads the stream until it has received one complete record. This piece of data is "cut loose" and processed in a new subprocess. For example, this could be an XSLT translation that then writes each record to a database.
Meanwhile, the reading and cutting in the iterator continues. It starts a new subprocess for each record that runs in parallel.
Why don't we just read the file?
Processing does not start after reading the entire file, but when the first record is read. The processing process starts a lot faster! If you read the entire file in memory, this will have a significant impact on the memory usage of your application with large files. In addition, it is possible to run all subprocesses in parallel for an even greater efficiency.
TO USE AN OUTPUT STREAM:
Write streaming to a CLOB database.
An adapter also handles the available OutputStreams smartly. For example, before processing a message an adapter goes through the entire pipeline to see if
there are building blocks that can offer an OutputStream. While processing a message, the pipeline does not start with the building block that wants to write data, but the building block where it is written to. This building block gives a "handle" to an OutputStream and makes it available to the pipe(s) in front of it. This ensures that during the processing of a message, the data does not have to be temporarily stored in memory, but can be written directly to the OutputStream.
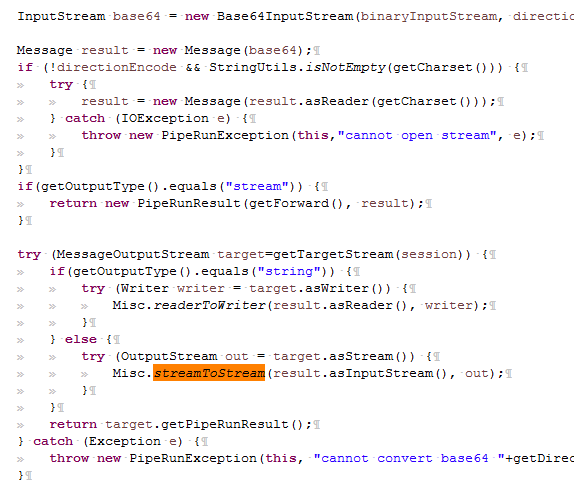
The streaming functionality is available from version 7.6 and is improved on version 7.7 of the Frank!Framework. As a Frank Developer, you don't really need to change anything about your adapter to work streaming. In- and OutputStreams are available for files, database objects and of course also for incoming HTTP requests.
Finally
In our latest release of the Frank! Framework (7.6) we offer standard streaming. Would you like more information? Contact us below for a consultation.
